
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- gitlab-ci
- Xen
- RPA
- Oracle
- UIPATH
- UiARD
- Git
- gitlab-runner
- MaxGauge
- UiPATH #UiRPA #RPA
- container-registry
- runner
- Shell
- docker
- gitlab
- sonar-qube
- PostgreSQL
- Today
- Total
목록2017 (23)
올챙이시절 기록소
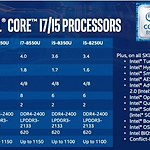 Intel CPU 8세대 - 커피레이크에 대한 개인적인 생각 ( 노트북 모델에 한해서 )
Intel CPU 8세대 - 커피레이크에 대한 개인적인 생각 ( 노트북 모델에 한해서 )
노트북을 사려는데 새로운 용어가 보였다 " 커피레이크 " 매년마다 발표하는 Intel의 CPU아키텍쳐이며 그간 보여주었던 성능차이는 아주 미미하였기에 ( * CPU 성능차이 비교 편 ) '뭐 그정도겠지' 라고 생각하였다 그러나 괄목상대 [刮目相對] 눈을 비비고 자료를 다시 찾아보았다 수치는 분명했다 사실상 지금 다들 사용하는 Desktop과 크게 차이가 없는 수준까지 왔다 이런 혁신이 나오다니!( 정확히는 카비레이크 7세대의 리프레시 버전이며, 코어와 쓰레드가 두 배씩 늘었으나 사용전력은 줄였다고 ) 지금이야 말로 노트북을 딱 사기좋은 적기가 아닐까 제조사들은 여러 포지션에서 각자의 제품을 내놓기 시작했다 지금 부터 찬찬히 살펴보면 좋은 가격에 만족스런 제품을 구매할 수 있을 것이다 개인적으론 i5 모델..
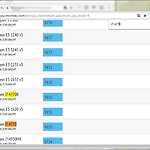 CPU 벤치마크 사이트 추천 ( Pass Mark vs CPU-Monkey )
CPU 벤치마크 사이트 추천 ( Pass Mark vs CPU-Monkey )
노트북이나 데스크탑 사양을 보는 것을 좋아하다보니 CPU벤치마크 점수를 가끔 비교해본다 'PassMark'란 사이트가 상당히 유명하고 노출빈도가 높아 접하기 쉽다 하지만 필자는 'CPU-MONKEY' 이 사이트를 이용한다 그 이유는 CPU의 성능군에 따라 HIgh, Mid, Low로 나누어져 있어 운이 좋으면 한 번에 찾겠지만 페이지를 바꿔가며 찾아봐야 하기에 노곤하다 그리고 디자인도 좀 촌스럽기하기 때문이다 반면에 사이트 이름(CPU-Monkey)은 촌스럽지만 CPU로고와 통일된 색감을 보여주어 훨씬 세련되어 보인다 CPU의 총 개수는 적지만 보편적으로 사용하는 대부분이 한 페이지 있어 검색도 편리하다 개별 CPU 정보를 클릭해보았을 때에도 이렇게 세부정보를 확인 할 수 있다 PS. 바로가기가 날아가서..
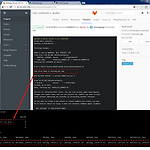 빌드서버 동작을 위한 쿼리와 함수 리스트
빌드서버 동작을 위한 쿼리와 함수 리스트
가장 먼저하는 것은 DB에 빌드 요구조건 명세 세팅 & Pipeline API 호출 0. DB & GitLab CI - API Call## SQLsinsert into mfo_tag values( baseline 및 컴포넌트 tag 값들 );insert into requirer values('QA','REPO','total','baseline'); update runner_stat set total_ver='baseline' where run_comp='mfototal_win';update runner_stat set value='1' where run_comp='mfototal_win'; ## VALUE=## 1 require## 2 Compile&Build## 3 Send File to require..
 Gitlab-CI API 사용하기 & Access Token 만들기
Gitlab-CI API 사용하기 & Access Token 만들기
CI 프로세스를 Event Base로 수행한다 9개 Repository를 이용해 빌드를 하다보니 각 콤포넌트의 버전을 세팅하고 읽어올 데가 필요했다 그래서 DB를 세팅을 하고 거기에 테이블을 만든 다음 빌드 명세를 세팅하면 빌드서버에서 조회하여 각 콤퍼넌트의 소스코드의 버전을 맞춘다 그리고 파이프라인을 돌리면 되는데 Master 브랜치 둔 다음 Create Pipeline 버튼을 누르는 것이다 API를 쓰게 되면 매번 누르지 않아도 된다 절차는 1.토큰생성2. CALL API 명령구문 생성 인증을 위해 토큰을 하나 만들어야 한다 Create Personal Access Token 버튼을 눌러 토큰을 생성하자 Your New Personal Access Token 항목이 생겼다 그러면서 이렇게 토큰값이 보..
 Sonar-Qube API 사용하기
Sonar-Qube API 사용하기
추가된 코드에 대한 분석 결과치 값을 파싱하여 채팅앱에 그 결과를 보여주고자 했었는데 API 쓰는 방법을 이틀 정도 연구하여 마침내 찾았다 vi mfodg/sonar-project.properties # must be unique in a given SonarQube instance sonar.projectKey=mfo:mfodg sonar.projectName=mfodg (data_gather) sonar.projectVersion=mfodg_170920.01 sonar.sources=. # Encoding of the source code. Default is default system encoding #sonar.sourceEncoding=UTF-8 http://10.10.32.101:9000/ap..
 Sonar-Qube 5.6 (on CentOS) 설치 & 정적분석 실행하기
Sonar-Qube 5.6 (on CentOS) 설치 & 정적분석 실행하기
CI의 프로세스의 한 부분으로 쓰기에 유용한 소나큐브 이 녀석을 설치하고 한 번 수행하는 예제를 보여드리겠다 설치는 간단하기에 절차를 따로 나누지 않는다 Requirementref : sonar_qube_docs JAVA는 1.8 버전이 필요하다. DB는 아래의 리스트에 있는 것을 사용하거나 아니면 설치하지 않아도 된다. 이때는 embedded DB를 사용하는데 H2라고하는 메모리 DB를 사용한다. ( 개인적인 생각으로는 형상관리의 필요성을 느끼지 못하여 DB를 구축하진 않았다 ) ( Gitlab을 사용하는 중이라면 PostgreSQL이 내장되어 있으니 연계해도 좋을 것이다 ) Sonar-Qube & Sonar-Scanner 설치 $ mkdir -p /app/sonarqube깔끔한 설치를 위해 경로를 하..
 리눅스에서 링크주소로 받기 ( wget -O 쌈박하게 파일 옮기는 법 )
리눅스에서 링크주소로 받기 ( wget -O 쌈박하게 파일 옮기는 법 )
외국 형아들이 터미널 다루는걸 보다가 멋지다 생각해서 메모를 해두었던 내용이다 sonar qube설치를 가이드 작성을 위해 설치파일을 다운받는 상황이었다 wget -O 받을파일이름설정 링크주소 받은 파일은 잘 unzip되었다
 Postgresql 9.6 on Windows 커맨드라인으로 설치하기 ( gitlab-ci 빌드 동작 중 한 파트 )
Postgresql 9.6 on Windows 커맨드라인으로 설치하기 ( gitlab-ci 빌드 동작 중 한 파트 )
빌드스크립트 중 Postgresql DB를 설치하는 부분이다 2016년 1월 PG를 폴더 째 형상관리하는 것이 비효율적이며 기술적으로 어려운부분이 많아 매번 설치 및 삭제하는 것으로 로직을 변경하였다 PG는 크게 EDB 와 BigSQL 두 곳에서 파일을 제공하고 있다 EDB에서 다운받은 installer가 불가사의한 이유로 XEN에서 설치가 불가하여 BigSQL로 갈아탔다 먼저, 인스톨러에 관련된 커맨드라인 옵션을 공부한다, 그리고 3개의 버전에 해당하는 9.4.10 ( install_pg94101.bat )9.6.1 ( install_pg9611.bat )9.6.3 ( install_pg9631.bat ) 자동 설치 스크립트를 작성하였다 install_pg94101.bat set PG_ROOT_HOME..
 GitLab - Group 프로젝트를 다른그룹에 또 포함 시키려 할 때 ( share with group )
GitLab - Group 프로젝트를 다른그룹에 또 포함 시키려 할 때 ( share with group )
gitlab을 관리하는 일 중에는 유저들에게 적절한 권한을 주는 일도 있다 이럴 때 간편히 작업하기 위해서 Group을 미리 지어놓는데 mfo ( maxgauge for oracle ) 제품군의 qa라면 mfo 그룹에 할당하면 된다 그러면 아래의 프로젝트에 권한이 한 번에 할당되는데 개발자의 경우는 조금 달라진다 여러제품군에 동일 부류의 컴포넌트를 담당하기에 mfodg(maxgauge for oracle data gather )mftdg ( maxgauge for tibero data gather )mfddg ( maxgauge for db2 data gather ) data gather 개발자의 경우 아래와 같은 그룹에 할당되어야 하는데 해당프로젝트의 Setting > Members > Share wi..
 Gitlab - PostgreSQL 접속하기 ( Direct access to Gitlab Database )
Gitlab - PostgreSQL 접속하기 ( Direct access to Gitlab Database )
본 글은 GitLab설치(Omnibus Package Installation)를 한 경우에 대해 다룬다 설치한 Gitlab의 Components섹션에 보면 PostgreSQL 9.6.3이 포함되어 있다 Team DB가 필요하여 여기를 써보려는 시도를 했었는데 오늘 우연히 자료를 찾았다 GitLab 서버에서 sudo -u gitlab-psql /opt/gitlab/embedded/bin/psql -h /var/opt/gitlab/postgresql/ gitlabhq_production 이렇게 입력하면 접속이된다 table들이 어떻게 있는지 보았고 이전에 등록했던 CI runner들의 데이터가 잘 저장되었는지 확인해보았다 select * from pg_tables; select description from..